Efficient inference without trading-off regret in bandits: An allocation probability test for Thompson sampling
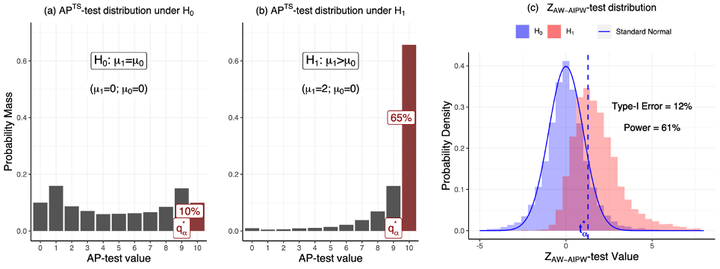 Image credit: Unsplash
Image credit: Unsplash
Abstract
Using bandit algorithms to conduct adaptive randomised experiments can minimise regret, but it poses major challenges for statistical inference (e.g., biased estimators, inflated type-I error and reduced power). Recent attempts to address these challenges typically impose restrictions on the exploitative nature of the bandit algorithm−trading off regret−and require large sample sizes to ensure asymptotic guarantees. However, large experiments generally follow a successful pilot study, which is tightly constrained in its size or duration. Increasing power in such small pilot experiments, without limiting the adaptive nature of the algorithm, can allow promising interventions to reach a larger experimental phase. In this work we introduce a novel hypothesis test, uniquely based on the allocation probabilities of the bandit algorithm, and without constraining its exploitative nature or requiring a minimum experimental size. We characterise our Allocation Probability Test when applied to Thompson Sampling, presenting its asymptotic theoretical properties, and illustrating its finite-sample performances compared to state-of-the-art approaches. We demonstrate the regret and inferential advantages of our approach, particularly in small samples, in both extensive simulations and in a real-world experiment on mental health aspects.